Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Brownian Motion
Part of my regular motherboard review testing is to tackle the Brownian motion of particles. This considers one of two physical scenarios - either gas in a vacuum or a dissolved substance in a fluid, where those particles that are free to move can do so. These particles can collide with the medium they are in, each other or the boundaries – in general the system can bypass all these by using the diffusion coefficient (average speed of a particle in a medium). However, the simulation should be probing at least one of them – with the first two situations requiring greater computational complexity than dealing with interactions on a surface.
The movement of these particles is the main computational element of this type of simulation – dealing with either free motion (mean free path in a random direction) or directed motion (applied force on top of free motion). Motion should start with a method to calculate which direction the particle is to travel in, and then any applied force simulated on top – the initial method is at the whim of random number generators and the choice of algorithm. In my original article I go through several methods of generating random motion described in the literature, as well as choosing an appropriate random number generator (too many published methods use basic C++ generators that repeat themselves after a few thousand calls). For simulating, we have various methods:
- If the simulation has a fixed number of time steps, calculate the random numbers before the simulation and use memory calls in the movement algorithm
- Calculate the random numbers on the fly during the algorithm if the time steps for each particle can vary (i.e. no need to track a particle after it collides with a surface)
In our Brownian motion benchmark (3D Particle Movement), we test the six different algorithms used in the literature for random direction movement in both single thread and multithreaded mode. The simulation generates a number of particles, each with its own thread. The thread iterates the particle through a fixed number of steps, and discards the particle. When all the threads have finished, the simulation checks the time to see if 10 seconds have passed - if the 10 seconds are not up, it goes through another loop. Results are then expressed in the form of million particle movements per second for each algorithm, and the total score is the sum of all the algorithms.
This benchmark is wholly memory independent – by generating random numbers on the fly, each thread can keep the position of the particle and the random number values in local cache.
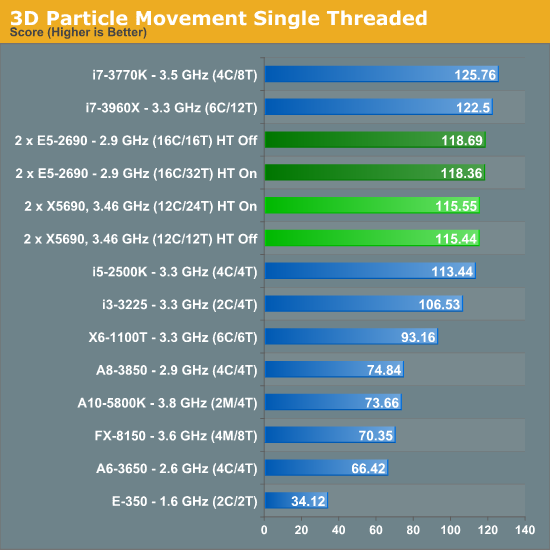
The difference in architectures is most plain to see in our single thread test – both the X5690 and E5-2690 will be applying maximum turbo (3.73 GHz and 3.8 GHz respectively) to similar clocks, meaning the IPC improvements of Sandy Bridge-E give it a 2.5% increase overall despite a mild (1.8%) clock increase.
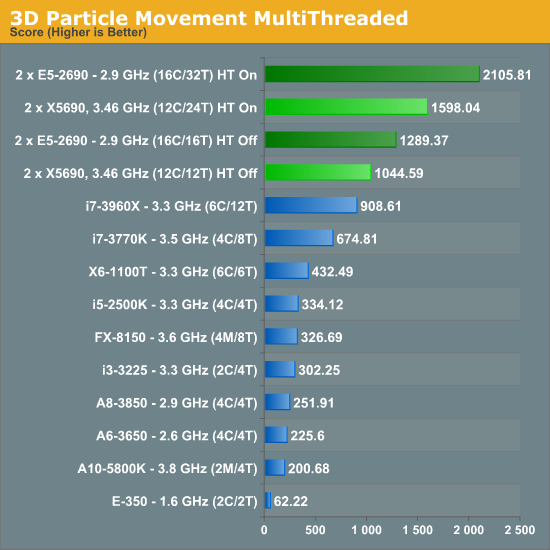
The advantages of more cores for this sort of simulation are plain to see, with the E5-2690 (despite a clock speed difference at full load of 2.9 GHz compared to 3.46 GHz) giving a 32% better result than the X5690.
n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions.
n-Body simulation is a large field of calculation with many different computational methods optimized for speed, memory usage or bus transfer – this is on top of the different algorithms that can be used to represent such a scenario. Typically one might expect the running time of a simulation be O(n^2) as each particle in the simulation has to interact gravitationally with every other particle, but some computational methods can be used to reduce this as the effect of gravity is inversely proportional to the square of the distance, and thus only the localized area needs to be known. Other complex solutions deal with general relativity. I am neither an expert in gravity simulations or relativity, but the solution used today is the full O(n^2) solution.
Part of the available code online for C++ AMP revolves around n-body simulations, as the basis of an n-body simulation maps nicely to parallel processors such as multi-CPU platforms and GPUs. For this review, I was able to strip out the code from the n-body example provided and run some numbers. Many thanks to Boby George and Jonathan Emmett from Microsoft for their help.
The code provided detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

As the n-body example deals with GFLOPs as a result, the numbers were only ever going to be in favor of the E5-2690s, with a 37% increase over the X5690s. Core count, IPC and memory speed play a role with large O(n2) simulations like these. Oddly enough, while HT Off was preferable on the E5-2690s, HT On gives a better result for X5690s.








44 Comments
View All Comments
SatishJ - Monday, March 4, 2013 - link
It would be only fair to compare X5690 with E5-2667. I suspect in this case the performance difference would not be earth-shattering. No doubt E5-2690 excels but then it has advantage of more cores / threads.wiyosaya - Monday, March 4, 2013 - link
There is a possible path forward for those dealing with "old" FORTRAN code. CUDA FORTRAN - http://www.pgroup.com/resources/cudafortran.htmI would expect that there would be some conversion issues, however, I would also expect that they would be lesser than converting to C++ or some other CUDA/openCL compliant language.
As much as some of us might like it to be, FORTRAN is not dead, yet!
mayankleoboy1 - Monday, March 4, 2013 - link
1. Why not use 7Zip for the compression benchmark ? Most HPC people would like to use a FREE, Highly threaded software for their work.2.Using 3770K @ 5.4 Ghz as a comparison point is foolish. Any Ivy bride processor above ~4.6 on air is unrealistic. And for HPC, no body will use a overclocked system.
Senti - Monday, March 4, 2013 - link
WinRar is interesting because it's very sensitive to memory subsystem (7zip is less so), but 3.93 is absolutely useless as it utilizes about half of my cpu time and the end result it turns into powersaving impact benchmark before anything else. AT promised to upgrade sometime this year, but before it we'll continue to have one less useful benchmark.Not overclocking your cpu when you have good cooling is plain waste of resources. Of course I mean not extreme overclocks, but permanent maximum "turbo" frequency should be your minimum goal.
SetiroN - Monday, March 4, 2013 - link
Sorry but...-So what?
Being "sensitive to memory" doesn't make a worse benchmark better, or free;
-So what?
Nobody will ever have good enough cooling to be able to compute daily at 5.4, which is FAR above max turbo anyway. Overclocked results are welcome, provided that I don't need an additional $500 phase change cooler and $100+ in monthly bills.
tynopik - Monday, March 4, 2013 - link
> Being "sensitive to memory" doesn't make a worse benchmark better, or free;It makes it better if your software is also sensitive to memory speed
different benchmarks that measure different aspects of performance are a GOOD thing
Death666Angel - Monday, March 4, 2013 - link
The OC CPU I see as a data point for his statement that some workloads don't require multi socket CPU systems but rather a single high IPC CPU. It may or may not be unrealistic for the target demographic, but it does add a data point for or against such a thing.IanCutress - Tuesday, March 5, 2013 - link
1. WinZip 3.93 has been part of my benchmark suite for the past 18 months (so lots of comparison numbers can be scrutinized), and is the one I personally use :) We should be updating to 4.2 for Haswell, though going back and testing the last few years of chipsets and various processors takes some time.2. My inhouse retail CPU does 4.9 GHz on air, easy :) But most of the OC numbers are courtesy of several HWBot overclockers at Overclock.net who volunteered to help as part of the testing. For them the bigger score the better, hence the overclocks on something other than ambient.
Ian
mayankleoboy1 - Monday, March 4, 2013 - link
How many real world workloads are using hand-coded AVX software ?How many use compiler optimized AVX software ?
What is the perf difference between them?
Not directly related to this article, but how many softwares have the AMD Bulldozer/piledriver optimised FMA and BMI extensions ?
Kevin G - Monday, March 4, 2013 - link
What is going on with the Explicit Finite Difference tests? The thing that stood out to me are the two results for the i7 3770K at 4.5 Ghz with memory speed being the differentiating factor. Going from 2000 Mhz to 2600 Mhz effective speed on the memory increased performance by ~13% in the 2D tests and ~6% in the 3D tests. Another thing worth pointing out is that the divider in Ivy Bridge has higher throughput than Sandy Bridge. This would account for some of the exceedingly high performance of the desktop Ivy Bridge systems if the algorithms make heavy use of division. The dual socket systems likely need some tuning with regards to their memory systems. The results of the dual socket systems are embarrassing in comparison to their 'lesser' single socket brethen.The implicit 2D test is similarly odd. The odd ball result is the Core i7 3820@4.2 Ghz against the Ivy bridge based Core i7 3770k@stock (3.5 Ghz). Despite the higher clock speed and extra memory channel, the consumer Sandy Bridge-E system loses! This is with the same number of cores and threads running. Just how much division are these algorithms using? That is the only thing that I can fathom to explain these differences. Multi-socket configurations are similarly nerfed with the implicit 2D test as they are with the explicit 2D test.
Did the Browian Motion simulations take advantage of Ivy Bridge's hardware random number generator? Looking at the results, signs are pointing toward 'no'.
I'm a bit nitpicky about the usage of the word 'element' describing the n-Body simulation with regards to gravity. The usage of element and particle are not technically incorrect but lead the reader to think that these simulations are done with data regarding the microscopic scales, not stellar.
The Xilisoft Video Converter test results seem to be erroneous. More than doubling the speed by enabling Hyperthreading? How is that even possible? Best case for Hypthereading is that half of the CPU execution resources are free so that another thread can utilize them and get double the throughput. HT rarely gets near twice as fast but these results imply five times faster which is outside the realm of possibility with everything else being equal. Scaling between the Core i7-3960k and the dual E5-2690 HT Off result looks off given how the results between other platforms look too.